The Only Guide You'd Ever Need for Load Balancers - 7
Sticky Sessions
Welcome back. If you’re coming from part 6, you now have a load balancer with multiple algorithms: Round Robin (RR), Weighted RR, Least Connections, Power of Two Choices, IP Hash.
But remember I mentioned IP Hash has a flaw? When a server dies, EVERYONE gets rerouted to different servers. Their sessions? Their progress on that big 67-step form? All gone.
In this part, we’re going to solve the session persistence problem properly. We’ll explore different strategies, and then I’ll show you Consistent Hashing.
The Stateful Application Problem
Most apps are still stateful. They remember things about you.
What is Session State?
When Sydney logs into our wingman dating app, the server creates a “session” for her:
┌─────────────────────────────────────────────────────────────────┐
│ │
│ Sydney's Session (stored on Server 1): │
│ │
│ { │
│ "session_id": "abc123xyz", │
│ "user_id": 42, │
│ "username": "sydney_looking_for_love", │
│ "logged_in_at": "2025-12-16T10:30:00Z", │
│ "shopping_cart": [ │
│ {"item": "Premium Membership", "price": 29.99}, │
│ {"item": "Profile Boost", "price": 9.99} │
│ ], │
│ "preferences": { │
│ "age_range": "25-35", │
│ "location": "New York" │
│ } │
│ } │
│ │
└─────────────────────────────────────────────────────────────────┘
This session lives on Server 1. Server 2 and Server 3 have no idea Sydney exists.
Why Random Distribution Breaks Sessions
With our RR or LC algorithms, Sydney’s requests go to different servers each time:
Sydney's journey through our load balancer:
Request 1: Login
├── Load Balancer picks Server 1
├── Server 1: "Welcome Sydney! Session created: abc123xyz"
├── Sydney: "cool, I'm in"
└── Session stored on Server 1
Request 2: Add item to cart
├── Load Balancer picks Server 2 (round robin, baby)
├── Server 2: "Who tf is Sydney? I don't have session abc123xyz"
├── Server 2: "Please log in"
├── Sydney: "But I just logged in??"
└── Session? What session?
Request 3: Try again
├── Load Balancer picks Server 3
├── Server 3: "I also don't know you"
├── Sydney: *quits*
└── We lost a customer
This is the classic stateful application problem. The session is on ONE server, but requests can go to ANY server.
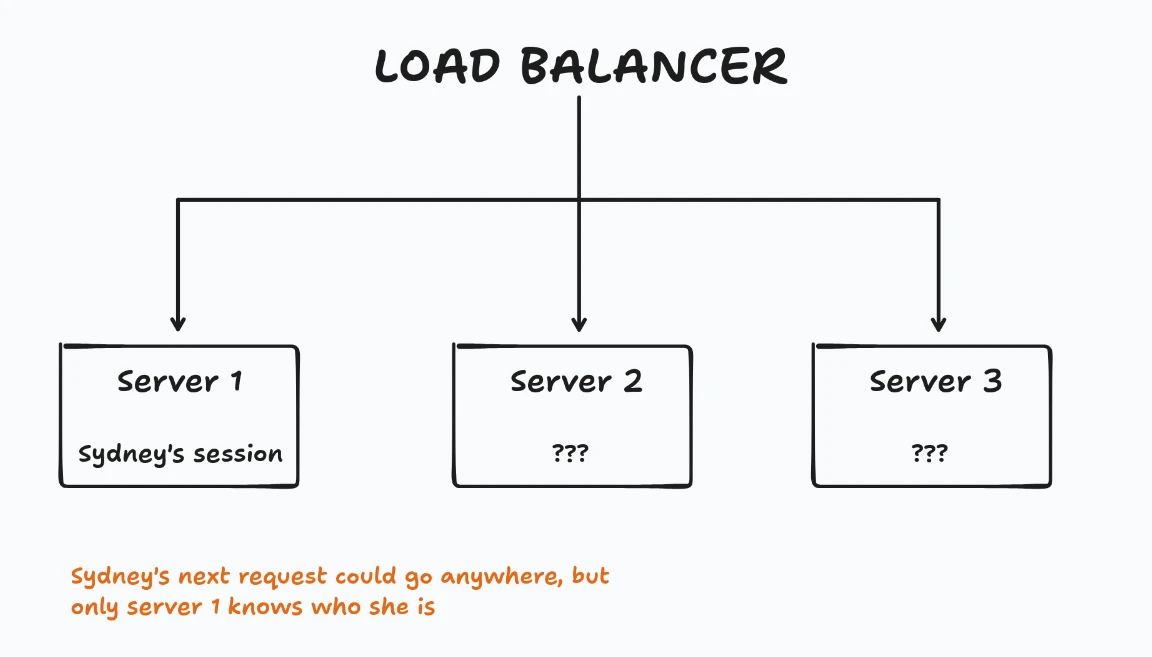
Session Persistence Strategies
There are multiple ways to solve this. Let’s go through them from simplest to most sophisticated.
Strategy 1: Source IP Affinity (IP Hash)
We covered this in Part 6. The idea: hash the client’s IP address to always route them to the same server.
hash("192.168.1.100") % 3 = 1 → Always Server 1
hash("10.0.0.55") % 3 = 0 → Always Server 0
The NAT Problem
But there’s a huge problem we didn’t discuss. What happens when multiple users share the same public IP?

With IP Hash:
hash("203.0.113.50") % 3 = 1
ALL 500 employees go to Server 1.
Server 2 and Server 3 are bored.
Server 1 is on fire.
This is called the “NAT problem” and it makes IP-based affinity unreliable for session persistence.
Other IP Affinity Problems
- Mobile users: Their IP changes as they move between networks (WiFi → cellular → different WiFi)
- Proxy users: Corporate proxies, VPNs, and CDNs change the apparent client IP
- IPv6 privacy extensions: Some clients rotate their IPv6 address frequently
IP Hash is simple but brittle. Let’s look at something better.
Strategy 2: Cookie-Based Persistence
Instead of relying on IP addresses, let’s use cookies. The load balancer inserts a cookie that identifies which backend server the client should stick to.
How It Works
┌─────────────────────────────────────────────────────────────────┐
│ │
│ First Request (no cookie): │
│ │
│ 1. Sydney → Load Balancer: "GET /login" │
│ │
│ 2. Load Balancer: "No sticky cookie, pick server normally" │
│ Round Robin says Server 2 │
│ │
│ 3. Load Balancer → Server 2: "GET /login" │
│ │
│ 4. Server 2 → Load Balancer: "200 OK, here's the page" │
│ │
│ 5. Load Balancer INSERTS cookie: │
│ Set-Cookie: SERVERID=server2; Path=/ │
│ │
│ 6. Load Balancer → Sydney: Response + sticky cookie │
│ │
└─────────────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────────────┐
│ │
│ Second Request (has cookie): │
│ │
│ 1. Sydney → Load Balancer: "GET /profile" │
│ Cookie: SERVERID=server2 │
│ │
│ 2. Load Balancer: "sticky cookie points to server2" │
│ Ignore normal algorithm, use Server 2 │
│ │
│ 3. Load Balancer → Server 2: "GET /profile" │
│ │
│ 4. Server 2: "problem fixed" │
│ Returns personalized response │
│ │
└─────────────────────────────────────────────────────────────────┘
Implementation
This requires Layer 7 (HTTP) awareness. Our current TCP proxy just forwards bytes and doesn’t understand HTTP. Let’s add HTTP parsing:
type CookieBasedPersistence struct {
cookieName string
backends map[string]*Backend
backendList []*Backend
algorithm Algorithm
mux sync.RWMutex
}
func NewCookieBasedPersistence(cookieName string, algo Algorithm) *CookieBasedPersistence {
return &CookieBasedPersistence{
cookieName: cookieName,
backends: make(map[string]*Backend),
backendList: make([]*Backend, 0),
algorithm: algo,
}
}
func (cbp *CookieBasedPersistence) AddBackend(name string, backend *Backend) {
cbp.mux.Lock()
defer cbp.mux.Unlock()
cbp.backends[name] = backend
cbp.backendList = append(cbp.backendList, backend)
}
func (cbp *CookieBasedPersistence) GetBackendFromCookie(cookieHeader string) *Backend {
cbp.mux.RLock()
defer cbp.mux.RUnlock()
cookies := strings.Split(cookieHeader, ";")
for _, cookie := range cookies {
cookie = strings.TrimSpace(cookie)
parts := strings.SplitN(cookie, "=", 2)
if len(parts) == 2 && parts[0] == cbp.cookieName {
serverName := parts[1]
if backend, ok := cbp.backends[serverName]; ok {
if backend.IsAlive() {
return backend
}
}
}
}
return nil
}
func (cbp *CookieBasedPersistence) GetBackendName(backend *Backend) string {
cbp.mux.RLock()
defer cbp.mux.RUnlock()
for name, b := range cbp.backends {
if b == backend {
return name
}
}
return ""
}
Now we need an HTTP-aware connection handler:
func (lb *LoadBalancer) handleHTTPConnection(clientConn net.Conn) {
defer clientConn.Close()
reader := bufio.NewReader(clientConn)
request, err := http.ReadRequest(reader)
if err != nil {
return
}
var backend *Backend
cookieHeader := request.Header.Get("Cookie")
if cbp, ok := lb.persistence.(*CookieBasedPersistence); ok && cookieHeader != "" {
backend = cbp.GetBackendFromCookie(cookieHeader)
}
if backend == nil {
backend = lb.algorithm.Next()
}
if backend == nil {
clientConn.Write([]byte("HTTP/1.1 503 Service Unavailable\r\n\r\n"))
return
}
backend.IncrementConnections()
defer backend.DecrementConnections()
backendConn, err := net.Dial("tcp", backend.Address())
if err != nil {
clientConn.Write([]byte("HTTP/1.1 502 Bad Gateway\r\n\r\n"))
return
}
defer backendConn.Close()
request.Write(backendConn)
backendReader := bufio.NewReader(backendConn)
response, err := http.ReadResponse(backendReader, request)
if err != nil {
return
}
if cbp, ok := lb.persistence.(*CookieBasedPersistence); ok {
if request.Header.Get("Cookie") == "" || cbp.GetBackendFromCookie(cookieHeader) == nil {
serverName := cbp.GetBackendName(backend)
if serverName != "" {
cookie := fmt.Sprintf("%s=%s; Path=/", cbp.cookieName, serverName)
response.Header.Add("Set-Cookie", cookie)
}
}
}
response.Write(clientConn)
}
Cookie Encoding and Security
In production, you don’t want to expose your server names in cookies. Anyone can see SERVERID=server2 and know your infrastructure.
Better approaches:
Option 1: Encode the server identifier
Instead of: SERVERID=server2
Use: SERVERID=aGVsbG8gd29ybGQ= (base64)
Or: SERVERID=5f4dcc3b5aa765d61d8327deb882cf99 (hash)
Option 2: Use signed cookies
SERVERID=server2.signature
Where signature = HMAC(server2, secret_key)
Load balancer verifies signature before trusting
Option 3: Encrypted cookies
SERVERID=encrypted_blob
Only load balancer can decrypt
Strategy 3: Application-Level Session IDs
Instead of the load balancer managing persistence, let the application handle it. The application includes a session ID in requests, and the load balancer routes based on that.
┌─────────────────────────────────────────────────────────────────┐
│ │
│ Request with session ID in header: │
│ │
│ GET /profile HTTP/1.1 │
│ Host: www.wingmandating.com │
│ X-Session-ID: sess_abc123xyz │
│ │
│ Load Balancer: hash("sess_abc123xyz") → Server 2 │
│ │
└─────────────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────────────┐
│ │
│ Request with session ID in URL: │
│ │
│ GET /profile?session=sess_abc123xyz HTTP/1.1 │
│ Host: www.wingmandating.com │
│ │
│ Load Balancer: parse URL, extract session, hash → Server 2 │
│ │
└─────────────────────────────────────────────────────────────────┘
This approach requires cooperation between application and load balancer. It’s more work but gives more control.
The REAL Problem
Here’s the thing. ALL of the above approaches (IP Hash, cookies, session IDs) share a fundamental problem:
What happens when a server is added or removed?
Let’s say you’re using IP Hash (or hashing session IDs, same principle):
BEFORE: 3 servers
hash(client) % 3 = server_index
Client A: hash → 7, 7 % 3 = 1 → Server 1
Client B: hash → 12, 12 % 3 = 0 → Server 0
Client C: hash → 5, 5 % 3 = 2 → Server 2
Client D: hash → 9, 9 % 3 = 0 → Server 0
Client E: hash → 4, 4 % 3 = 1 → Server 1
Now Server 2 dies:
AFTER: 2 servers
hash(client) % 2 = server_index
Client A: hash → 7, 7 % 2 = 1 → Server 1 (same!)
Client B: hash → 12, 12 % 2 = 0 → Server 0 (same!)
Client C: hash → 5, 5 % 2 = 1 → Server 1 (WAS Server 2, moved!)
Client D: hash → 9, 9 % 2 = 1 → Server 1 (WAS Server 0, moved!)
Client E: hash → 4, 4 % 2 = 0 → Server 0 (WAS Server 1, moved!)
3 out of 5 clients got remapped to different servers!
In general, with simple modulo hashing, when you change from N to N-1 servers, approximately (N-1)/N of all clients get remapped. For 100 servers, that’s 99% of clients losing their sessions!
This is horrible. We need something better.
Consistent Hashing
Consistent hashing is one of those algorithms that makes you say “why didn’t I think of that?” It minimizes the number of keys that need to be remapped when servers change.
The Core Concept
Instead of hash % N, imagine arranging all possible hash values on a circle (a “ring”):
Now, here’s the key idea:
- Hash the servers and place them on the ring
- Hash the clients and place them on the ring
- Each client goes to the first server clockwise from its position
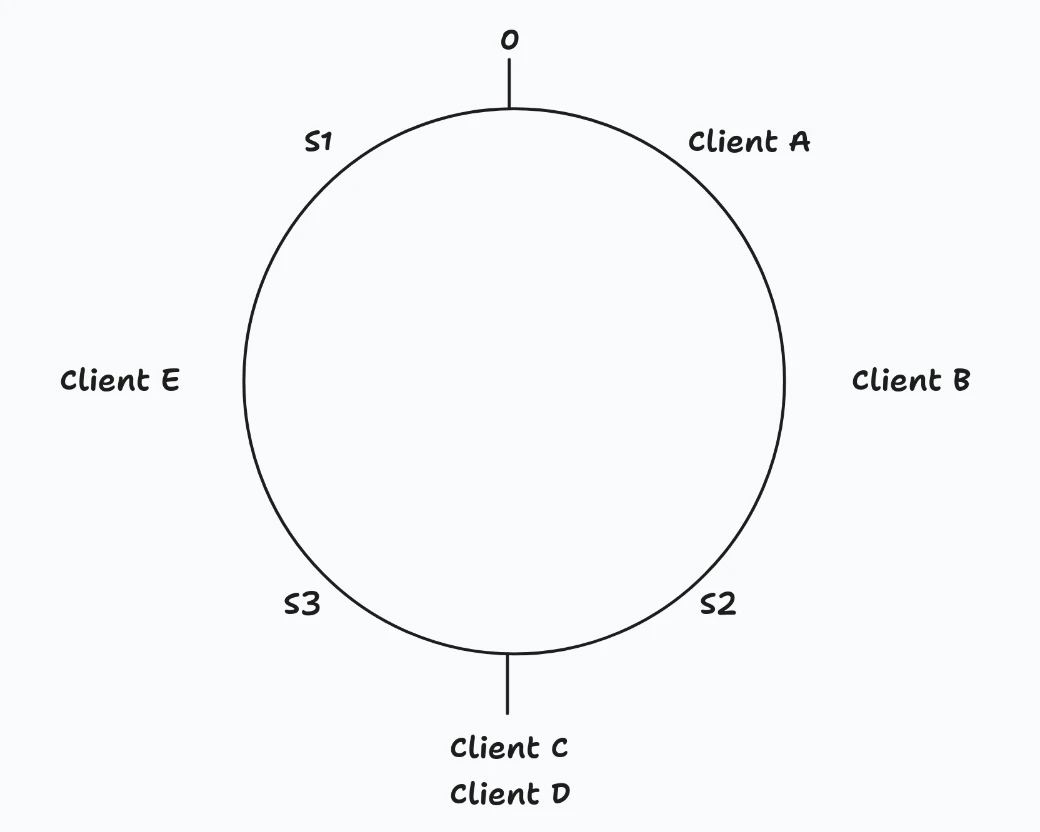
┌─────────────────────────────────────────────────────────────────┐
│ Servers: S1, S2, S3 (placed by hashing their names) │
│ Clients: A, B, C, D, E (placed by hashing their IPs/IDs) │
│ │
│ Routing (go clockwise to find server): │
│ - Client A → S2 (next server clockwise) │
│ - Client B → S2 │
│ - Client C → S3 │
│ - Client D → S3 │
│ - Client E → S1 │
└─────────────────────────────────────────────────────────────────┘
What Happens When a Server Dies?
Let’s say S2 dies:
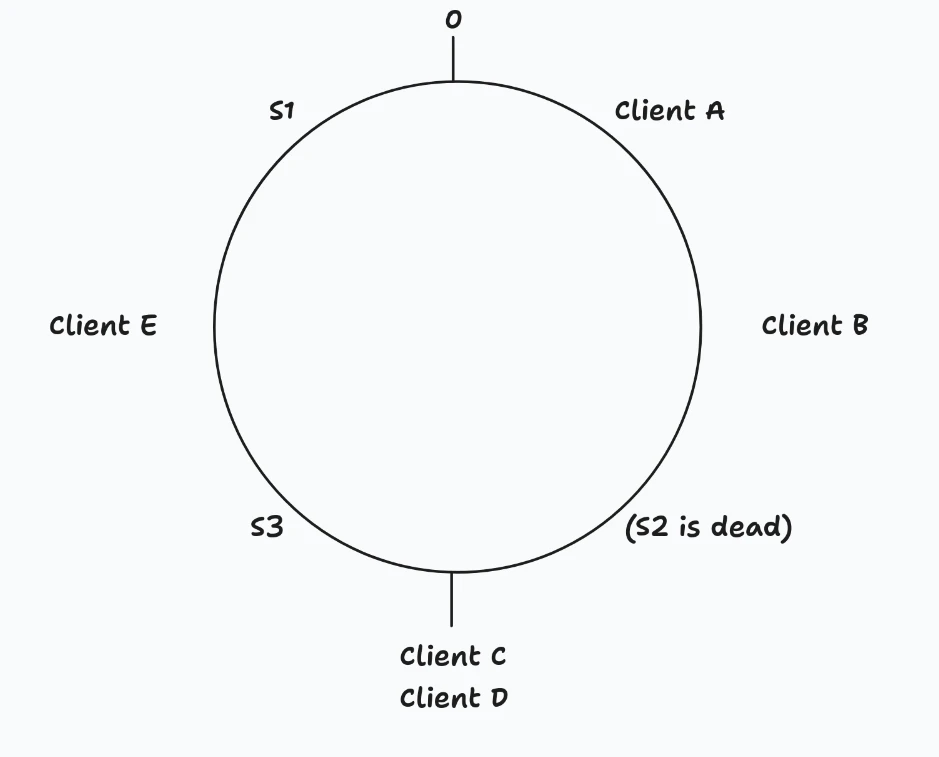
┌─────────────────────────────────────────────────────────────────┐
│ After S2 dies: │
│ - Client A → S3 (was S2, MOVED) │
│ - Client B → S3 (was S2, MOVED) │
│ - Client C → S3 (same!) │
│ - Client D → S3 (same!) │
│ - Client E → S1 (same!) │
│ │
│ Only clients that were on S2 moved │
│ Clients on S1 and S3 are unaffected │
└─────────────────────────────────────────────────────────────────┘
Only the clients that were assigned to S2 need to move. Everyone else stays put. This is HUGE.
With N servers and K keys:
- Simple modulo: ~K keys remapped when a server changes
- Consistent hashing: ~K/N keys remapped when a server changes
For 100 servers and 1 million sessions, that’s the difference between remapping ~1 million sessions vs ~10,000 sessions.
The Virtual Nodes Problem
But wait, there’s still a problem. What if the servers aren’t evenly distributed on the ring? There could be cases where all three servers are clustered together, and say, S3 handles almost all traffic, while S1 and S2 barely get any traffic
Virtual Nodes to the Rescue
Instead of placing each server once on the ring, place it multiple times at different positions. These are called virtual nodes.
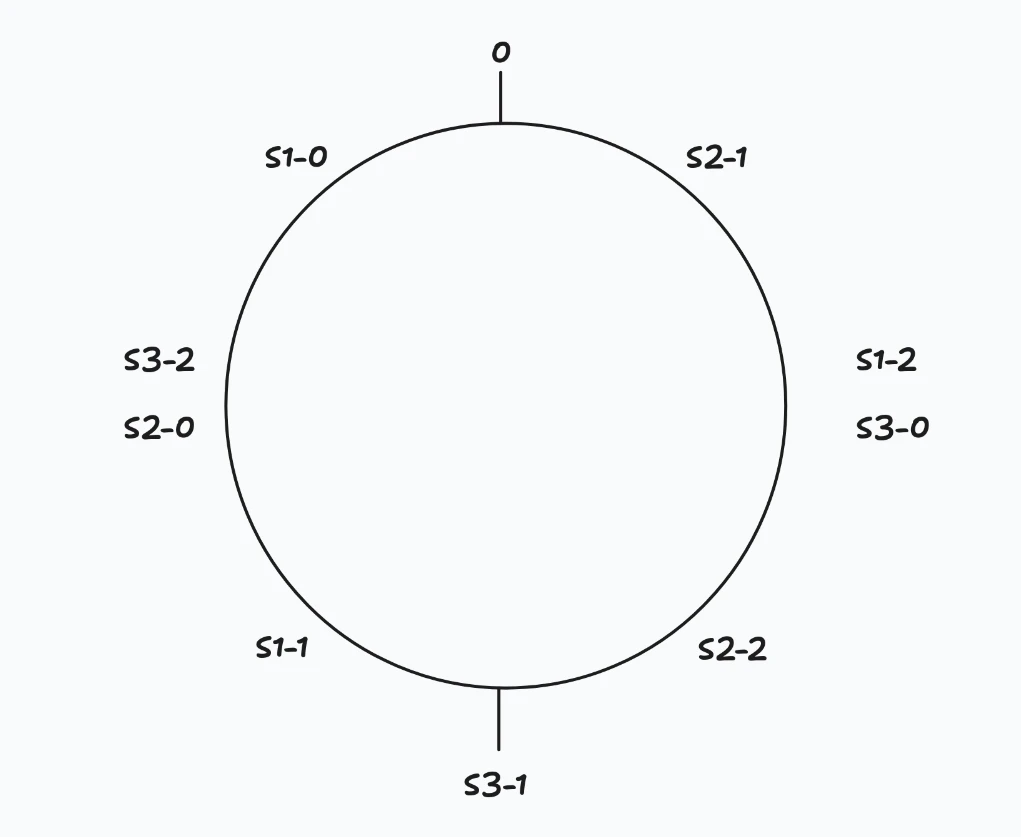
┌─────────────────────────────────────────────────────────────────┐
│ │
│ Each server gets multiple positions (virtual nodes): │
│ │
│ Server 1: hash("S1-0"), hash("S1-1"), hash("S1-2"), ... │
│ Server 2: hash("S2-0"), hash("S2-1"), hash("S2-2"), ... │
│ Server 3: hash("S3-0"), hash("S3-1"), hash("S3-2"), ... │
│ │
│ Now load is evenly distributed │
│ Each server has multiple "claims" on the ring │
└─────────────────────────────────────────────────────────────────┘
With enough virtual nodes (even if it’s 100-200), the distribution becomes very even.
Implementing Consistent Hashing
Let’s write the code:
package main
import (
"hash/crc32"
"sort"
"sync"
)
type ConsistentHash struct {
circle map[uint32]*Backend
sortedHashes []uint32
virtualNodes int
backends []*Backend
mux sync.RWMutex
}
func NewConsistentHash(virtualNodes int) *ConsistentHash {
return &ConsistentHash{
circle: make(map[uint32]*Backend),
sortedHashes: make([]uint32, 0),
virtualNodes: virtualNodes,
backends: make([]*Backend, 0),
}
}
func (ch *ConsistentHash) hashKey(key string) uint32 {
return crc32.ChecksumIEEE([]byte(key))
}
func (ch *ConsistentHash) AddBackend(backend *Backend) {
ch.mux.Lock()
defer ch.mux.Unlock()
ch.backends = append(ch.backends, backend)
for i := 0; i < ch.virtualNodes; i++ {
virtualKey := fmt.Sprintf("%s:%d:%d", backend.Host, backend.Port, i)
hash := ch.hashKey(virtualKey)
ch.circle[hash] = backend
ch.sortedHashes = append(ch.sortedHashes, hash)
}
sort.Slice(ch.sortedHashes, func(i, j int) bool {
return ch.sortedHashes[i] < ch.sortedHashes[j]
})
}
func (ch *ConsistentHash) RemoveBackend(backend *Backend) {
ch.mux.Lock()
defer ch.mux.Unlock()
for i, b := range ch.backends {
if b == backend {
ch.backends = append(ch.backends[:i], ch.backends[i+1:]...)
break
}
}
for i := 0; i < ch.virtualNodes; i++ {
virtualKey := fmt.Sprintf("%s:%d:%d", backend.Host, backend.Port, i)
hash := ch.hashKey(virtualKey)
delete(ch.circle, hash)
}
ch.sortedHashes = make([]uint32, 0, len(ch.circle))
for hash := range ch.circle {
ch.sortedHashes = append(ch.sortedHashes, hash)
}
sort.Slice(ch.sortedHashes, func(i, j int) bool {
return ch.sortedHashes[i] < ch.sortedHashes[j]
})
}
func (ch *ConsistentHash) GetBackend(key string) *Backend {
ch.mux.RLock()
defer ch.mux.RUnlock()
if len(ch.sortedHashes) == 0 {
return nil
}
hash := ch.hashKey(key)
idx := sort.Search(len(ch.sortedHashes), func(i int) bool {
return ch.sortedHashes[i] >= hash
})
if idx >= len(ch.sortedHashes) {
idx = 0
}
startIdx := idx
for {
backend := ch.circle[ch.sortedHashes[idx]]
if backend.IsAlive() {
return backend
}
idx = (idx + 1) % len(ch.sortedHashes)
if idx == startIdx {
return nil
}
}
}
func (ch *ConsistentHash) GetBackendForIP(clientIP string) *Backend {
return ch.GetBackend(clientIP)
}
func (ch *ConsistentHash) GetBackendForSession(sessionID string) *Backend {
return ch.GetBackend(sessionID)
}
Testing Consistent Hashing
Let’s verify it actually minimizes remapping:
func TestConsistentHashRemapping() {
ch := NewConsistentHash(150)
s1 := NewBackend("server1", 8081)
s2 := NewBackend("server2", 8082)
s3 := NewBackend("server3", 8083)
ch.AddBackend(s1)
ch.AddBackend(s2)
ch.AddBackend(s3)
clients := make([]string, 10000)
for i := 0; i < 10000; i++ {
clients[i] = fmt.Sprintf("client-%d", i)
}
initialMapping := make(map[string]*Backend)
for _, client := range clients {
initialMapping[client] = ch.GetBackend(client)
}
countBefore := make(map[*Backend]int)
for _, backend := range initialMapping {
countBefore[backend]++
}
fmt.Println("Before removal:")
fmt.Printf(" Server 1: %d clients\n", countBefore[s1])
fmt.Printf(" Server 2: %d clients\n", countBefore[s2])
fmt.Printf(" Server 3: %d clients\n", countBefore[s3])
ch.RemoveBackend(s2)
remapped := 0
for _, client := range clients {
newBackend := ch.GetBackend(client)
if initialMapping[client] != newBackend {
remapped++
}
}
fmt.Printf("\nAfter removing Server 2:\n")
fmt.Printf(" Clients remapped: %d / %d (%.1f%%)\n",
remapped, len(clients), float64(remapped)/float64(len(clients))*100)
}
Output:
Before removal:
Server 1: 3342 clients
Server 2: 3315 clients
Server 3: 3343 clients
After removing Server 2:
Clients remapped: 3315 / 10000 (33.2%)
Only the clients that were on Server 2 got remapped. The math checks out.
The Full Load Balancer with Consistent Hashing
Let’s integrate it:
type LoadBalancer struct {
host string
port int
consistentHash *ConsistentHash
pool *ServerPool
}
func NewLoadBalancer(host string, port int, virtualNodes int) *LoadBalancer {
return &LoadBalancer{
host: host,
port: port,
consistentHash: NewConsistentHash(virtualNodes),
pool: NewServerPool(),
}
}
func (lb *LoadBalancer) AddBackend(host string, port int) *Backend {
backend := lb.pool.AddBackend(host, port)
lb.consistentHash.AddBackend(backend)
return backend
}
func (lb *LoadBalancer) handleConnection(clientConn net.Conn) {
defer clientConn.Close()
clientAddr := clientConn.RemoteAddr().String()
clientIP, _, _ := net.SplitHostPort(clientAddr)
backend := lb.consistentHash.GetBackendForIP(clientIP)
if backend == nil {
clientConn.Write([]byte("HTTP/1.1 503 Service Unavailable\r\n\r\n"))
return
}
log.Printf("[LB] %s → %s (consistent hash)", clientIP, backend.Address())
backend.IncrementConnections()
defer backend.DecrementConnections()
backendConn, err := net.Dial("tcp", backend.Address())
if err != nil {
clientConn.Write([]byte("HTTP/1.1 502 Bad Gateway\r\n\r\n"))
return
}
defer backendConn.Close()
lb.forwardTraffic(clientConn, backendConn)
}
Session Draining
What happens when you need to take a server offline for maintenance? You don’t want to just kill everyone’s sessions.
Session draining is the process of gracefully removing a server:
- Stop sending NEW requests to the server
- Let existing connections finish
- After a timeout (or all connections close), remove the server
┌─────────────────────────────────────────────────────────────────┐
│ │
│ Session Draining Timeline: │
│ │
│ T=0: Admin initiates drain on Server 2 │
│ ├── Server 2 marked as "draining" │
│ ├── New requests go to other servers │
│ └── Existing connections continue │
│ │
│ T=0 to T=30s: Drain period │
│ ├── Active connections on Server 2: 150 → 89 → 34 → 12 │
│ └── Users finish their tasks naturally │
│ │
│ T=30s: Drain timeout │
│ ├── 12 connections still active │
│ ├── Option A: Force close remaining connections │
│ └── Option B: Extend timeout │
│ │
│ T=35s: Server 2 removed completely │
│ └── Now safe to shut down │
│ │
└─────────────────────────────────────────────────────────────────┘
Implementation
type Backend struct {
Host string
Port int
alive int32
draining int32 // new field!
connections int64
}
func (b *Backend) IsDraining() bool {
return atomic.LoadInt32(&b.draining) == 1
}
func (b *Backend) SetDraining(draining bool) {
var v int32 = 0
if draining {
v = 1
}
atomic.StoreInt32(&b.draining, v)
}
func (b *Backend) IsAvailable() bool {
return b.IsAlive() && !b.IsDraining()
}
func (lb *LoadBalancer) DrainBackend(backend *Backend, timeout time.Duration) {
log.Printf("[DRAIN] Starting drain for %s (timeout: %v)", backend.Address(), timeout)
backend.SetDraining(true)
deadline := time.Now().Add(timeout)
ticker := time.NewTicker(1 * time.Second)
defer ticker.Stop()
for {
conns := backend.GetConnections()
if conns == 0 {
log.Printf("[DRAIN] %s drained successfully (0 connections)", backend.Address())
break
}
if time.Now().After(deadline) {
log.Printf("[DRAIN] %s drain timeout, %d connections remaining",
backend.Address(), conns)
break
}
log.Printf("[DRAIN] %s: %d connections remaining", backend.Address(), conns)
<-ticker.C
}
lb.consistentHash.RemoveBackend(backend)
log.Printf("[DRAIN] %s removed from pool", backend.Address())
}
Update GetBackend to skip draining servers for new connections:
func (ch *ConsistentHash) GetBackend(key string) *Backend {
ch.mux.RLock()
defer ch.mux.RUnlock()
if len(ch.sortedHashes) == 0 {
return nil
}
hash := ch.hashKey(key)
idx := sort.Search(len(ch.sortedHashes), func(i int) bool {
return ch.sortedHashes[i] >= hash
})
if idx >= len(ch.sortedHashes) {
idx = 0
}
startIdx := idx
for {
backend := ch.circle[ch.sortedHashes[idx]]
if backend.IsAvailable() {
return backend
}
idx = (idx + 1) % len(ch.sortedHashes)
if idx == startIdx {
return nil
}
}
}
When NOT to Use Sticky Sessions
Here’s the truth that might hurt: sticky sessions are often a band-aid for poor architecture.
In a perfect world, your application would be stateless. Session state would live in a shared store, not on individual servers.
Stateless Architecture
┌─────────────────────────────────────────────────────────────────┐
│ │
│ STATEFUL (what we've been building for): │
│ │
│ ┌─────────────────────────────────────────┐ │
│ │ Load Balancer │ │
│ │ (sticky sessions required) │ │
│ └─────────────────────────────────────────┘ │
│ │ │
│ ┌─────────────┼─────────────┐ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Server 1 │ │ Server 2 │ │ Server 3 │ │
│ │ │ │ │ │ │ │
│ │ Sydney's │ │ Mike's │ │ Sara's │ │
│ │ Session │ │ Session │ │ Session │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │
│ Problem: Sessions are local. Server dies = sessions die. │
│ │
└─────────────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────────────┐
│ │
│ STATELESS (the better way): │
│ │
│ ┌───────────────────────────┐ │
│ │ Load Balancer │ │
│ └───────────────────────────┘ │
│ │ │
│ ┌─────────────┼─────────────┐ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Server 1 │ │ Server 2 │ │ Server 3 │ │
│ │ │ │ │ │ │ │
│ │ (no │ │ (no │ │ (no │ │
│ │ state) │ │ state) │ │ state) │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │ │ │ │
│ └─────────────┼─────────────┘ │
│ │ │
│ ▼ │
│ ┌────────────────────┐ │
│ │ Shared Session │ │
│ │ Store (Redis) │ │
│ │ │ │
│ │ All sessions here │ │
│ └────────────────────┘ │
│ │
│ Any server can handle any request. │
│ Server dies = no problem, sessions are safe in Redis. │
│ │
└─────────────────────────────────────────────────────────────────┘
Benefits of Stateless
- Any server can handle any request - No routing constraints
- Server failure doesn’t lose sessions - Data is in shared store
- Easy horizontal scaling - Just add more servers
- Better algorithms - Can use Least Connections, Power of Two Choices, etc.
- Simpler load balancer - No need for sticky logic
When You Still Need Sticky Sessions
Sometimes stateless isn’t practical:
- Legacy applications - Rewriting for stateless is too expensive
- WebSocket connections - Long-lived connections need to stay with one server
- In-memory caches - Local caches warm up over time, better to keep users on same server
- Large session data - Too expensive to store/retrieve from shared store every request
Complete Implementation
Here’s our load balancer with all session persistence strategies:
package main
import (
"bufio"
"fmt"
"hash/crc32"
"io"
"log"
"net"
"net/http"
"sort"
"strings"
"sync"
"sync/atomic"
"time"
)
type Backend struct {
Host string
Port int
alive int32
draining int32
connections int64
}
func NewBackend(host string, port int) *Backend {
return &Backend{
Host: host,
Port: port,
alive: 1,
}
}
func (b *Backend) Address() string {
return fmt.Sprintf("%s:%d", b.Host, b.Port)
}
func (b *Backend) IsAlive() bool {
return atomic.LoadInt32(&b.alive) == 1
}
func (b *Backend) SetAlive(alive bool) {
var v int32 = 0
if alive {
v = 1
}
atomic.StoreInt32(&b.alive, v)
}
func (b *Backend) IsDraining() bool {
return atomic.LoadInt32(&b.draining) == 1
}
func (b *Backend) SetDraining(draining bool) {
var v int32 = 0
if draining {
v = 1
}
atomic.StoreInt32(&b.draining, v)
}
func (b *Backend) IsAvailable() bool {
return b.IsAlive() && !b.IsDraining()
}
func (b *Backend) GetConnections() int64 {
return atomic.LoadInt64(&b.connections)
}
func (b *Backend) IncrementConnections() {
atomic.AddInt64(&b.connections, 1)
}
func (b *Backend) DecrementConnections() {
atomic.AddInt64(&b.connections, -1)
}
type ConsistentHash struct {
circle map[uint32]*Backend
sortedHashes []uint32
virtualNodes int
backends []*Backend
backendNames map[*Backend]string
mux sync.RWMutex
}
func NewConsistentHash(virtualNodes int) *ConsistentHash {
return &ConsistentHash{
circle: make(map[uint32]*Backend),
sortedHashes: make([]uint32, 0),
virtualNodes: virtualNodes,
backends: make([]*Backend, 0),
backendNames: make(map[*Backend]string),
}
}
func (ch *ConsistentHash) hashKey(key string) uint32 {
return crc32.ChecksumIEEE([]byte(key))
}
func (ch *ConsistentHash) AddBackend(name string, backend *Backend) {
ch.mux.Lock()
defer ch.mux.Unlock()
ch.backends = append(ch.backends, backend)
ch.backendNames[backend] = name
for i := 0; i < ch.virtualNodes; i++ {
virtualKey := fmt.Sprintf("%s-%d", name, i)
hash := ch.hashKey(virtualKey)
ch.circle[hash] = backend
ch.sortedHashes = append(ch.sortedHashes, hash)
}
sort.Slice(ch.sortedHashes, func(i, j int) bool {
return ch.sortedHashes[i] < ch.sortedHashes[j]
})
log.Printf("[HASH] Added %s with %d virtual nodes", name, ch.virtualNodes)
}
func (ch *ConsistentHash) RemoveBackend(backend *Backend) {
ch.mux.Lock()
defer ch.mux.Unlock()
name := ch.backendNames[backend]
for i, b := range ch.backends {
if b == backend {
ch.backends = append(ch.backends[:i], ch.backends[i+1:]...)
break
}
}
for i := 0; i < ch.virtualNodes; i++ {
virtualKey := fmt.Sprintf("%s-%d", name, i)
hash := ch.hashKey(virtualKey)
delete(ch.circle, hash)
}
delete(ch.backendNames, backend)
ch.sortedHashes = make([]uint32, 0, len(ch.circle))
for hash := range ch.circle {
ch.sortedHashes = append(ch.sortedHashes, hash)
}
sort.Slice(ch.sortedHashes, func(i, j int) bool {
return ch.sortedHashes[i] < ch.sortedHashes[j]
})
log.Printf("[HASH] Removed %s", name)
}
func (ch *ConsistentHash) GetBackend(key string) *Backend {
ch.mux.RLock()
defer ch.mux.RUnlock()
if len(ch.sortedHashes) == 0 {
return nil
}
hash := ch.hashKey(key)
idx := sort.Search(len(ch.sortedHashes), func(i int) bool {
return ch.sortedHashes[i] >= hash
})
if idx >= len(ch.sortedHashes) {
idx = 0
}
startIdx := idx
for {
backend := ch.circle[ch.sortedHashes[idx]]
if backend.IsAvailable() {
return backend
}
idx = (idx + 1) % len(ch.sortedHashes)
if idx == startIdx {
return nil
}
}
}
func (ch *ConsistentHash) GetBackendName(backend *Backend) string {
ch.mux.RLock()
defer ch.mux.RUnlock()
return ch.backendNames[backend]
}
type CookiePersistence struct {
cookieName string
consistentHash *ConsistentHash
}
func NewCookiePersistence(cookieName string, ch *ConsistentHash) *CookiePersistence {
return &CookiePersistence{
cookieName: cookieName,
consistentHash: ch,
}
}
func (cp *CookiePersistence) GetBackendFromCookie(cookieHeader string) *Backend {
cookies := strings.Split(cookieHeader, ";")
for _, cookie := range cookies {
cookie = strings.TrimSpace(cookie)
parts := strings.SplitN(cookie, "=", 2)
if len(parts) == 2 && parts[0] == cp.cookieName {
return cp.consistentHash.GetBackend(parts[1])
}
}
return nil
}
type HealthChecker struct {
backends []*Backend
interval time.Duration
timeout time.Duration
failThreshold int
riseThreshold int
failCounts map[*Backend]int
successCounts map[*Backend]int
mux sync.Mutex
}
func NewHealthChecker(backends []*Backend) *HealthChecker {
return &HealthChecker{
backends: backends,
interval: 5 * time.Second,
timeout: 3 * time.Second,
failThreshold: 3,
riseThreshold: 2,
failCounts: make(map[*Backend]int),
successCounts: make(map[*Backend]int),
}
}
func (hc *HealthChecker) check(b *Backend) bool {
client := &http.Client{Timeout: hc.timeout}
resp, err := client.Get(fmt.Sprintf("http://%s/health", b.Address()))
if err != nil {
return false
}
defer resp.Body.Close()
return resp.StatusCode >= 200 && resp.StatusCode < 300
}
func (hc *HealthChecker) process(b *Backend, healthy bool) {
hc.mux.Lock()
defer hc.mux.Unlock()
wasAlive := b.IsAlive()
if healthy {
hc.failCounts[b] = 0
hc.successCounts[b]++
if !wasAlive && hc.successCounts[b] >= hc.riseThreshold {
b.SetAlive(true)
log.Printf("[HEALTH] %s is now HEALTHY", b.Address())
hc.successCounts[b] = 0
}
} else {
hc.successCounts[b] = 0
hc.failCounts[b]++
if wasAlive && hc.failCounts[b] >= hc.failThreshold {
b.SetAlive(false)
log.Printf("[HEALTH] %s is now UNHEALTHY", b.Address())
hc.failCounts[b] = 0
}
}
}
func (hc *HealthChecker) Start() {
log.Printf("[HEALTH] Starting health checker")
ticker := time.NewTicker(hc.interval)
hc.checkAll()
for range ticker.C {
hc.checkAll()
}
}
func (hc *HealthChecker) checkAll() {
var wg sync.WaitGroup
for _, b := range hc.backends {
wg.Add(1)
go func(backend *Backend) {
defer wg.Done()
hc.process(backend, hc.check(backend))
}(b)
}
wg.Wait()
}
type LoadBalancer struct {
host string
port int
consistentHash *ConsistentHash
cookiePersistence *CookiePersistence
backends []*Backend
}
func NewLoadBalancer(host string, port int, virtualNodes int) *LoadBalancer {
ch := NewConsistentHash(virtualNodes)
return &LoadBalancer{
host: host,
port: port,
consistentHash: ch,
cookiePersistence: NewCookiePersistence("SERVERID", ch),
backends: make([]*Backend, 0),
}
}
func (lb *LoadBalancer) AddBackend(name, host string, port int) *Backend {
backend := NewBackend(host, port)
lb.backends = append(lb.backends, backend)
lb.consistentHash.AddBackend(name, backend)
return backend
}
func (lb *LoadBalancer) DrainBackend(backend *Backend, timeout time.Duration) {
log.Printf("[DRAIN] Starting drain for %s", backend.Address())
backend.SetDraining(true)
deadline := time.Now().Add(timeout)
ticker := time.NewTicker(1 * time.Second)
defer ticker.Stop()
for {
conns := backend.GetConnections()
if conns == 0 {
log.Printf("[DRAIN] %s drained successfully", backend.Address())
break
}
if time.Now().After(deadline) {
log.Printf("[DRAIN] %s timeout, %d connections remaining", backend.Address(), conns)
break
}
log.Printf("[DRAIN] %s: %d connections remaining", backend.Address(), conns)
<-ticker.C
}
lb.consistentHash.RemoveBackend(backend)
}
func (lb *LoadBalancer) Start() error {
addr := fmt.Sprintf("%s:%d", lb.host, lb.port)
listener, err := net.Listen("tcp", addr)
if err != nil {
return err
}
defer listener.Close()
log.Printf("[LB] Started on %s with consistent hashing", addr)
for {
conn, err := listener.Accept()
if err != nil {
log.Printf("[LB] Accept error: %v", err)
continue
}
go lb.handleHTTPConnection(conn)
}
}
func (lb *LoadBalancer) handleHTTPConnection(clientConn net.Conn) {
defer clientConn.Close()
reader := bufio.NewReader(clientConn)
request, err := http.ReadRequest(reader)
if err != nil {
return
}
clientAddr := clientConn.RemoteAddr().String()
clientIP, _, _ := net.SplitHostPort(clientAddr)
var backend *Backend
cookieHeader := request.Header.Get("Cookie")
if cookieHeader != "" {
backend = lb.cookiePersistence.GetBackendFromCookie(cookieHeader)
if backend != nil {
log.Printf("[LB] %s → %s (cookie)", clientIP, backend.Address())
}
}
if backend == nil {
backend = lb.consistentHash.GetBackend(clientIP)
if backend != nil {
log.Printf("[LB] %s → %s (consistent hash)", clientIP, backend.Address())
}
}
if backend == nil {
clientConn.Write([]byte("HTTP/1.1 503 Service Unavailable\r\n\r\n"))
return
}
backend.IncrementConnections()
defer backend.DecrementConnections()
backendConn, err := net.Dial("tcp", backend.Address())
if err != nil {
clientConn.Write([]byte("HTTP/1.1 502 Bad Gateway\r\n\r\n"))
return
}
defer backendConn.Close()
request.Write(backendConn)
backendReader := bufio.NewReader(backendConn)
response, err := http.ReadResponse(backendReader, request)
if err != nil {
return
}
serverName := lb.consistentHash.GetBackendName(backend)
if serverName != "" {
cookie := fmt.Sprintf("%s=%s; Path=/; HttpOnly", lb.cookiePersistence.cookieName, serverName)
response.Header.Add("Set-Cookie", cookie)
}
response.Write(clientConn)
}
func main() {
lb := NewLoadBalancer("0.0.0.0", 8080, 150)
lb.AddBackend("server1", "127.0.0.1", 8081)
lb.AddBackend("server2", "127.0.0.1", 8082)
lb.AddBackend("server3", "127.0.0.1", 8083)
hc := NewHealthChecker(lb.backends)
go hc.Start()
// example: drain server2 after 30 seconds (for testing)
// go func() {
// time.Sleep(30 * time.Second)
// lb.DrainBackend(lb.backends[1], 60*time.Second)
// }()
if err := lb.Start(); err != nil {
log.Fatal(err)
}
}
Testing Session Persistence
Test 1: Consistent Hashing
Start the backends and load balancer, then make repeated requests:
for i in {1..10}; do
curl -s http://localhost:8080 | grep "Backend Server"
done
All requests should go to the same server (consistent hashing on IP).
Test 2: Cookie Persistence
curl -c cookies.txt -s http://localhost:8080 | grep "Backend Server"
for i in {1..5}; do
curl -b cookies.txt -s http://localhost:8080 | grep "Backend Server"
done
All requests should go to the same server (cookie persistence).
Test 3: Server Failure
while true; do
curl -b cookies.txt -s http://localhost:8080 | grep "Backend Server"
sleep 1
done
# in another terminal, kill the server you're connected to
# watch the requests automatically move to another server
With consistent hashing, only clients on the dead server get remapped.
Recap
We covered a lot:
The Problem:
- Stateful applications store sessions on individual servers
- Random load balancing breaks sessions
The Solutions:
| Strategy | Pros | Cons |
|---|---|---|
| IP Hash | Simple | NAT problem, IP changes |
| Cookies | Reliable | Layer 7 required, cookie management |
| Session ID routing | Most control | Requires app cooperation |
| Consistent Hashing | Minimal remapping | More complex to implement |
Key Concepts:
- Consistent Hashing minimizes session disruption when servers change
- Virtual Nodes ensure even distribution on the hash ring
- Session Draining gracefully removes servers without killing sessions
- Stateless Architecture is better when possible
What Now?
Our load balancer is getting pretty decent now. We’ve got:
- Multiple algorithms (RR, Weighted, LC, etc.)
- Health checking
- Session persistence with consistent hashing
- Cookie based sticky sessions
- Graceful draining
In the next part, we’re going to dive into Layer 4 vs Layer 7 Load Balancing. We’ve been doing a mix of both, but there are important distinctions and trade-offs to understand. We’ll explore when to use TCP-level load balancing vs HTTP-level load balancing.
As always, hit me up on X / Twitter if you have questions, found bugs, or want to discuss anything tech or design related!!
See you in part 8 :)